Image may be NSFW.
Clik here to view.
Florian Besson
Université Paris-Sorbonne
Doctorant à l’Université Paris-Sorbonne, je travaille sur la féodalité dans le royaume latin de Jérusalem, entre 1097 et 1228, en m’intéressant particulièrement à la société aristocratique, aux relations de pouvoir entre la noblesse et la royauté, à la façon dont les nobles contrôlent l’espace. Au cours de ces quelques semaines passées au Centre de Recherche Français de Jérusalem, dans le cadre d’une aide à la mobilité de la Fondation Bettencourt-Schueller, j’ai réfléchi sur plusieurs façons d’utiliser les potentialités offertes par Internet et, plus globalement, par les nouvelles technologies, pour présenter des sources, des données historiographiques, ou des cartes. Cette réflexion s’inscrit dans le long terme, et s’est nourrie notamment de nombreuses discussions avec des collègues et amis, doctorants ou professeurs, que je tiens à remercier ici[1].
Une vision synthétique des sources grâce aux nuages de mots
La présentation des sources est un passage obligé de la thèse, voire très souvent d’un livre, mais c’est souvent, aussi, un chapitre laborieux, à la fois pour l’auteur et pour le lecteur. Comment, en quelques lignes, résumer des œuvres souvent denses et complexes ? Cette difficulté, qu’on pourrait qualifier de pédagogique, se double souvent d’un autre enjeu : ces sources sont familières à l’auteur, qui, parfois durant plusieurs années, les a lues, étudiées, traduites souvent. La dimension affective du rapport aux sources ne doit être ni sous-estimée ni méprisée : chaque chercheur se sent attaché à « ses » sources, ce qui peut d’ailleurs parfois empêcher des contacts entre disciplines[2]. L’enjeu de leur présentation devient dès lors différent, puisqu’il va surtout s’agir de faire voir leur spécificité, leur originalité, sans cependant les isoler en en faisant des œuvres « uniques ».
Une façon originale et encore peu utilisée de présenter les sources pourrait alors être celle du nuage de mots (word cloud). Le nuage de mots est une image qui condense un document en dotant les concepts clefs de celui-ci d’une unité de taille : plus un mot est employé, plus il sera représenté avec une police importante. On peut utiliser plusieurs couleurs différentes pour mieux distinguer les mots.
Par exemple, voilà un nuage de mots réalisé à partir de cet article – une image à mi-chemin entre la mise en abyme et la bande annonce…
Image 1 (en tête d’article) : nuage de mots à partir de cet article
Historiquement, la technique du nuage de mots provient d’un système de visualisation de sites Webs, mise au point par Jim Flanagan, le Search Referral Zeitgeist. C’est le site de partage de photos Flickr qui fut le premier à utiliser cet outil, baptisé alors « système d’archivage transversal du contenu »[3]. La technique est depuis devenue très à la mode, et on la retrouve notamment dans la presse ou sur de nombreux blogs.
Plusieurs sites, accessibles en ligne, proposent de réaliser des nuages de mots. J’ai ici travaillé à partir du site Tagul (https://tagul.com/), qui propose de nombreuses fonctionnalités, et qui offre de plus l’avantage d’être gratuit – cependant, l’accès à des images de bonne définition reste payant. Le site permet également de pouvoir sauvegarder ses nuages, qu’ils soient terminés ou en cours de fabrication.
Clik here to view.

La démarche est on ne peut plus simple : il suffit de copier un document en format texte (.doc, .docx, .pdf, .odt), puis d’importer les mots en utilisant la fonction « coller ». La liste des mots apparaît alors ainsi :
Clik here to view.

C’est là qu’intervient le gros du travail en même temps que la nécessaire réflexion méthodologique. En effet, les mots sont classés par fréquence d’apparition : quel que soit le texte choisi, on aura donc un très grand nombre de mots tels que « et », « le », « un », « de »,… Il faut alors décider des mots qu’on garde. Parmi les difficultés posées, on peut aussi noter que les verbes apparaissent éclatés : pour une chronique de la première croisade, on aura ainsi « combattre », « combattra », « combattîmes », « combattirent », « combattent », et ainsi de suite, toutes ces formes renvoyant à la même racine. Faut-il alors fusionner tous ces mots en un seul, pour lui donner la visibilité qui lui revient ? La même question de pose pour le pluriel et le singulier : dans tous mes textes, on trouve « cheval » et « chevaux ». Faut-il n’en faire qu’un seul mot, qui sera dès lors plus visible, puisque plus fréquent ? Tagul permet en tout cas de telles manipulations : on peut changer la fréquence d’un mot, choisir sa couleur, sa police, son sens de lecture, et ainsi de suite. Il manque au site une fonction « recherche » qui permettrait de repérer rapidement des répétitions dans les mots importés ; j’ai pris contact avec les développeurs du site et cet outil devrait bientôt être disponible. Enfin, un nuage ne doit pas être surinterprété : il y a notamment un risque qui consisterait à écraser un terme rare, et donc important, sous la masse des mots plus fréquents. Pour prendre un exemple, si une chronique de la première croisade (1097-1099) employait le mot « Graal », même une seule fois, ce serait extrêmement important (en même temps qu’extrêmement vexant pour tous les fans de Chrétien de Troyes) ; or un tel terme ne serait pas visible dans un nuage de mots. Pour le dire autrement, cet outil ne remplacera jamais le contact approfondi et de première main avec les sources.
Cette technique, de plus, ne peut pas fonctionner avec toutes les sources : il faut un corpus à la fois homogène et d’une certaine ampleur. Les résultats seraient à la fois moins pertinents et moins intéressants pour les actes de la pratique, souvent trop courts pour qu’un nuage de mots soit pertinent.
Enfin, une autre question importante à poser est celle de la traduction : de nombreuses traductions, en particulier lorsqu’elles sont anciennes, ont tendance à s’écarter du texte. Certains termes latins uniques seront ainsi traduits différemment en fonction du contexte : l’exemple le plus fréquent est miles, traduit tantôt par cavalier, tantôt par chevalier. Pour que le nuage soit pertinent, il faut donc souvent reprendre soi-même la traduction. Dans l’idéal, il faudrait probablement réaliser un nuage de mots à partir du texte original, puis traduire ces termes – ce qui poserait un autre problème pour les textes latins, car il faudrait alors fusionner des mots qui, à cause des déclinaisons, apparaîtraient comme différents… Pour l’instant, j’ai donc choisi de travailler à partir des textes en français, la traduction étant de mon fait pour les sources en latin et en ancien français.
Le travail de tri peut donc être, en fonction de la taille du texte étudié, assez long et fastidieux, et doit être fait selon des critères précis, choisis en fonction du type d’informations que l’on souhaite mettre en valeur. Pour ce qui est de mes sources, j’ai choisi de ne retenir que les noms propres et les noms communs, et de fusionner les pluriels et les singuliers sous la seconde forme (ainsi, « chevaux » à 46 occurrences et « cheval » à 34 devient « cheval » à 80 occurrences). La décision de ne pas retenir les verbes, conjugués ou non, est avant tout une décision pratique visant à rendre le nuage plus lisible ; mais elle fait également sens sur le fond, puisqu’on ne retient ainsi que des concepts qui articulent l’ensemble du récit.
J’ai donc réalisé cette opération sur l’ensemble de mes sources, soit plus d’une quinzaine de chroniques, occidentales ou musulmanes, ainsi que plusieurs textes de lois. Le résultat final est extrêmement significatif.
Clik here to view.

Gesta Dei per Francos (c. 1106-1111)[4].
Clik here to view.
![Image 5 : nuage de mots à partir de l’Historia rerum in partibus transmarinis gestarum de Guillaume de Tyr (c. 1184)[5]](http://f.hypotheses.org/wp-content/blogs.dir/886/files/2016/01/5.jpeg)
Clik here to view.
![Image 6 : nuage de mots à partir de Usâma ibn Munqidh, Kitâb al-I’tibar[6] (c. 1187-1188).](http://f.hypotheses.org/wp-content/blogs.dir/886/files/2016/01/6.jpeg)
L’aspect de présentation synthétique d’une source est clairement atteint : un seul coup d’œil au nuage obtenu à partir du texte de Usâma ibn Munqidh suffit pour comprendre que c’est un texte autobiographique, dans lequel l’auteur parlera de lui et de sa vie. Le « je », en effet, domine de très loin, un aspect d’autant plus frappant que ce mot est presque entièrement absent des autres textes contemporains. Il suffit ensuite de quelques instant pour saisir les deux points dont il parle le plus : la guerre (« lance », « mort », « combat », « épée »…) et, surtout, la chasse, (« cheval », « faucon », « chasse », « lion »…). Il semblerait même possible de déterminer avec une assez grande précision la date et le contexte de rédaction de son œuvre : les noms propres (Damas, Zengui, Salâh ad-Dîn), certains noms communs renvoyant au paysage politique (« émir », « atabek ») ou l’importance du terme « Franc » suffisent à placer ce texte à l’époque des croisades. Cette opération mentale, qui prouve à elle seule l’efficacité visuelle du nuage de mots, serait d’ailleurs un exercice pédagogique extrêmement intéressant, qui permettrait à des élèves ou à des étudiants de retrouver le contexte d’une œuvre à partir de celle-ci, plutôt que de toujours étudier une œuvre à partir de son contexte. En renversant le sens de l’étude, on s’affranchirait de la dictature du contexte que critiquait notamment Pierre Bayard[7].
Si ces nuages peuvent ainsi permettre une saisie rapide de l’essence d’une œuvre, ils appellent surtout à des commentaires sur l’importance ou l’absence de tel ou tel mot. « Jérusalem » est par exemple toujours présent dans tous nos textes, mais n’occupe pas forcément la place qu’on attendrait, notamment dans des chroniques de la première croisade. Les termes renvoyant à Dieu sont toujours extrêmement nombreux, sous toutes leurs formes, ce qui ne doit pas surprendre étant donné l’état ecclésiastique de tous ces auteurs. Les nuages obtenus à partir des chroniques de la première croisade reflètent à merveille la propagande déployée par le seigneur normand Bohémond, dont le nom est souvent le seul à ressortir clairement[8]. Les mots employés renvoient aussi souvent à l’identité de l’auteur : Guillaume de Tyr et Guibert de Nogent emploient ainsi énormément de mots pour décrire la condition sociale des acteurs (voir l’importance, dans ces nuages, de « prince », « roi », « comte », « chevalier »,…), ce qui peut s’expliquer par le fait qu’ils appartiennent tous les deux, Guillaume par son statut d’archevêque et Guibert par sa naissance, à la noblesse.
Plus encore qu’un outil de présentation, les nuages de mots apparaissent ainsi comme des outils d’analyse, offrant de nouvelles façons de voir, au sens propre, des textes. La perspective annoncée au début de cette partie est dès lors inversée : il ne s’agit plus de faire voir à son lectorat des textes familiers, mais de les voir différemment, de les rendre étrangers, afin de mieux y revenir. Cette technique, cependant, ne peut prétendre remplacer une analyse appuyée sur des logiciels de lexicométrie, comme Lexico ou Hyperbase[9]. Avec les nuages de mots, l’analyse reste en quelque sorte impressionniste – mais les résultats sont impressionnants, et accessibles à tous, sans avoir besoin de se former aux méthodes statistiques[10], ni pour produire ces nuages, ni pour les interpréter.
- II) Saisir les évolutions historiographiques grâce à Ngram Viewer
Autre partie obligée de la thèse : la présentation de l’historiographie. C’est, là encore, une partie qui peut être tout aussi difficile à écrire que fastidieuse à lire. Et, là encore, on peut se tourner vers une nouvelle façon de la présenter – qui, tout comme les nuages de mots, n’exclura jamais, en aucun cas, une longue analyse.
Google Ngram Viewer (https://books.google.com/ngrams) est une application proposée sur Internet depuis 2010, qui permet de d’observer l’évolution de la fréquence d’un mot ou de plusieurs mots à travers le temps[11]. La recherche repose sur les livres numérisés par Google (« Google Books »), et pose donc plusieurs limites méthodologiques qu’il faut bien avoir en tête (notamment, un ouvrage peu édité sera aussi représenté qu’un ouvrage très largement diffusé ; il y a donc un risque de surreprésentation des mots rares). La recherche ne porte donc jamais sur l’ensemble des livres du monde, et ne prend pas non plus en compte les articles, ce qui est, pour nos disciplines, une sérieuse limite.
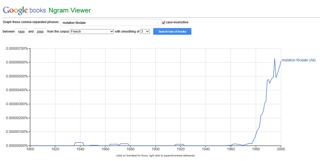
Une recherche toute simple permet de vérifier le bon fonctionnement de l’application : en tapant, par exemple, le mot « internet », on obtient cette courbe.
Clik here to view.

L’augmentation soudaine et très importante de la fréquence d’utilisation du mot est bien sûr ici entièrement logique, et même prévisible.
On peut dès lors utiliser cette application pour observer l’évolution de l’utilisation des concepts importants de sa recherche. Pour ce qui est de mon sujet, plusieurs recherches livrent des résultats intéressants : ainsi de « mutation féodale », qui donne cette courbe.
Clik here to view.
L’augmentation rapide du terme correspond à la sortie de l’ouvrage de Jean-Pierre Poly et Eric Bournazel, La Mutation féodale (Paris, PUF, 1980), qui engendra un intense débat connu aujourd’hui sous le nom de « querelle de la mutation (ou de la révolution) de l’an mil ». Le pic est atteint au milieu des années 1990, années qui voient les tenants et les opposants de cette thèse s’affronter à coups d’articles (notamment dans la revue Past and Present) ou d’ouvrages[12]. Le terme retombe vite au début du nouveau millénaire, mais rebondit ensuite, et preuve que le débat n’est pas terminé – même si la synthèse récente proposée par Florian Mazel devrait sérieusement permettre de le dépasser, sinon de le clore[13]. Présenter cette image permet ainsi de résumer l’importance de ce débat à un moment précis, résumé plus efficace qu’un long paragraphe de texte.
On peut ainsi observer la progressive montée en puissance d’un concept : ainsi, en cherchant « domination sociale », « interaction »[14], « potlatch », des concepts empruntés respectivement à Pierre Bourdieu, Erwin Goffman ou Marcel Mauss et que je mobilise dans mes recherches, on obtient à chaque fois une courbe globalement similaire, le terme étant de plus en plus employé, avec parfois des pics ou des creux.
Clik here to view.

Clik here to view.

Clik here to view.

L’application permet de mettre en lumière la rapidité ou l’influence d’un nouveau paradigme : le terme « linguistic turn » apparaît ainsi au début des années 1960, et est cent fois plus présent en 2000 qu’en 1980. Si certains concepts se maintiennent toujours à peu près au même niveau (ainsi de « croisade » ou de « violence »), d’autres peuvent passer de mode : le terme « féodalisme » connaît ainsi un pic très net dans les années 1960-1980, ce qui correspond probablement à l’apogée des réflexions autour du marxisme, et peut également renvoyer à l’activité de la Société d’études du féodalisme.
Clik here to view.

Certaines recherches mettent en valeur de lentes désaffections qui resteraient invisibles sans cette application : ainsi du terme « féodalité » qui, contrairement à ce que l’on pourrait penser, n’a cessé de décliner depuis le XIXème siècle. Dans le corpus « English », on observe la même chose pour le terme « lordship ». Ces évolutions traduisent ainsi une baisse d’intérêt pour des concepts qui restent pourtant centraux et dont on ne peut faire l’économie.
Clik here to view.

La comparaison entre la courbe d’emploi des termes « féodalisme » (image 12) et « féodalité » (image 13) est éclairante : elle rappelle utilement que les deux termes ne sont pas synonymes, et qu’ils ont eu un destin différent. Le premier renvoie le plus souvent à un mode de production basé sur l’exploitation de la terre par une classe de propriétaires exploitant une masse de travailleurs semi-libres[15]. La féodalité, quant à elle, désigne plutôt le système politique dont la principale caractéristique réside dans le fait que les seigneurs dominent à la fois la terre et les hommes, à travers des relations personnelles plus qu’institutionnelles. Ici, l’utilisation des courbes de fréquence invite ainsi à distinguer entre plusieurs concepts, et à prendre en compte l’histoire intellectuelle qui les sous-tend.
Enfin, pour prendre un dernier exemple, une courbe de fréquence peut aussi permettre un regard global sur une discipline : le terme « Moyen Âge » livre ainsi un résultat très curieux, avec une forte baisse entre 1945 et 1985, suivie d’une reprise rapide qu’il faut très probablement attribuer aux effets des travaux de Jacques Le Goff et de Georges Duby. Des œuvres capitales comme L’Imaginaire médiéval, du premier, et Guillaume le Maréchal du second sortent entre 1984 et 1985. Malgré cette récente augmentation, le terme reste moins employé qu’en 1945, et près de deux fois moins qu’au milieu du XIXème siècle – un constat qui s’explique évidemment par plusieurs biais d’observation[16], mais qui invite aussi à faire preuve d’humilité et à s’interroger sur l’utilité sociale de l’histoire médiévale[17].
Clik here to view.

Comme pour les nuages de mots, les images ainsi obtenues ne disent pas tout. Elles appellent, d’abord, à de solides explications méthodologiques : pourquoi ces mots-là, pourquoi ces dates-là, etc. Forcément incomplètes et partiales, elles nécessitent aussi des explications et, comme les nuages de mots, servent autant à offrir une vision immédiate d’un point précis qu’à servir de base de départ pour des analyses intéressantes.
III) Réaliser des cartes interactives
Cette dernière réflexion est la plus prometteuse, mais aussi la plus complexe, et, de ce fait, la moins aboutie. Je ne fais donc qu’en présenter les grandes lignes. L’idée serait de pouvoir proposer des cartes « interactives », c’est-à-dire des cartes qui ne seraient pas seulement des illustrations, mais qui pourraient porter des informations, auxquelles l’utilisateur aurait accès en cliquant sur certaines parties de la carte (raison pour laquelle on parle aussi de « cartes cliquables »). Très utilisées aujourd’hui (un exemple ici http://whc.unesco.org/fr/carte-interactive/), les cartes interactives n’en restent pas moins difficiles à réaliser. Il faut en effet non seulement produire ses propres cartes, mais ensuite les coder en utilisant différents logiciels.
Mes cartes sont réalisées à partir du logiciel Inkscape, un logiciel de dessin vectoriel qui permet de produire des images d’une excellente résolution, et qui, de plus, est gratuit (disponible au téléchargement ici https://inkscape.org/en/). J’ai ensuite testé plusieurs logiciels, notamment Raphaël et Xia, mais les résultats n’étaient pas pleinement satisfaisants, en particulier à cause de la résolution finale de l’image obtenue. J’ai finalement opté pour Gimp (http://www.gimp.org/), un logiciel de traitement d’image qui permet également de produire des cartes cliquables.
La démarche à suivre est assez lourde. Après avoir réalisé une carte sous Inkscape, il faut l’exporter en bitmap (format .png), l’ouvrir avec Gimp, utiliser le filtre « carte cliquable » pour ouvrir une nouvelle fenêtre qui permettra de définir des zones cliquables et de taper le texte qui s’affichera lorsque le lecteur passera sa souris sur ces zones. Après plusieurs manipulations sur le détail desquelles je passe ici, on peut enregistrer sa carte, sous un format .html. Il faut alors utiliser un éditeur de textes, par exemple Notepad, pour retoucher les lignes de code. La carte est alors prête à être ouverte avec un navigateur internet.
Un exemple rapide : j’ai ainsi pu produire une carte de Césarée avec Inkscape. Insérée telle quelle dans la thèse, la carte se présenterait ainsi.
Clik here to view.

En suivant la manipulation que je viens d’exposer, on peut réaliser une carte cliquable sur laquelle on fait figurer des informations supplémentaires : des dates, des informations bibliographiques, des liens renvoyant à d’autres pages web ou à des images que l’on aura préalablement stockées sur un site de partage de fichiers, tel que Google Drive.
Pour l’instant, cette carte interactive, volontairement très basique, est accessible à cette adresse : http://perso.crans.org/besson/cartes/cesaree/[18]. Certains navigateurs peuvent refuser d’afficher l’image ; de plus, elle peut s’afficher en très gros en fonction des réglages de votre ordinateur : il suffit alors de dézoomer en utilisant Ctrl-.
Clik here to view.

La carte peut ainsi servir de point de départ à toutes sortes d’explications et d’analyses. Cette technique servirait aussi à relier plusieurs cartes ensemble, ce qui permettrait de croiser les échelles d’une façon rapide et fluide, ou de faire voir l’évolution historique, une approche très utile lorsque certaines villes changent de main, entre Francs et musulmans, plusieurs fois en quelques années.
La difficulté réside ensuite dans l’accessibilité de cette carte. En effet, on obtient au final un fichier .html, qu’il faut conserver dans un dossier spécial. À terme, le plus simple sera probablement de construire un site internet sur lequel seront hébergées l’ensemble des cartes et les métadonnées qui s’y rapportent ; je n’ai pas encore eu le temps de me pencher sur cet aspect de la question, qui pose des problèmes à la fois pratiques et méthodologiques : ce site doit-il être accessible à tous ou seulement à un lectorat choisi ? Comment concilier lecture sur papier, encore privilégiée dans nos disciplines littéraires, et utilisation d’un contenu enrichi de cette sorte ?
Conclusion
J’ai souhaité proposer trois outils qui permettent de produire des images qui ne seraient pas seulement des illustrations mais qui serviraient également à apporter un véritable contenu scientifique. Ces trois outils – les nuages de mots, les courbes de fréquence d’utilisation d’un mot et les cartes interactives – ont plusieurs points communs sur lesquels il peut être intéressant de revenir rapidement pour finir.
Tout d’abord, tous trois produisent des images, qui peuvent être insérées dans un article – comme on l’a fait ici – mais qui gagnent surtout à être utilisées en ligne. En effet, des liens peuvent être insérés sur chaque mot d’un nuage de mots : on peut renvoyer à une définition, à un exemple, à un article. De même, Ngram Viewer propose, en cliquant sur un point de la courbe, d’obtenir la liste des livres utilisant le mot recherché lors de cette année-là : c’est donc aussi un bon moyen d’explorer rapidement une bibliographie, voire même de repérer des titres. Une courbe de fréquence d’utilisation d’un mot peut donc jouer comme une véritable porte d’entrée dans la galaxie, sans cesse plus vaste et plus touffue, des livres accessibles en ligne. Enfin, une carte cliquable n’est, par définition, utilisable qu’en ligne. Ces trois outils permettent donc d’enrichir la lecture, ce qui n’est pas, on l’a dit, sans poser de réelles questions – quid du livre écrit ? Ces nouvelles formes de lecture rejoignent des expérimentations récentes : l’Histoire du Monde au XVème siècle, dirigée par Patrick Boucheron[19], proposait ainsi dans la marge des liens vers d’autres chapitres, jouant comme de véritables liens hypertextes qui offraient des parcours de lecture littéralement infinis. Plus récemment, Ivan Jablonka invitait à repenser les rapports entre histoire, écriture et fiction, en utilisant à plein les potentialités offertes notamment par Internet. L’enjeu est de taille : comme le note I. Jablonka, il s’agit ni plus ni moins de réussir à « réinventer notre métier »[20]. Cet article se veut une modeste contribution à cet appel stimulant.
Ces images ont un autre point commun : elles fonctionnent sur le même mode, celui de l’évidence. C’est là en effet la grande force, en même temps que le grand risque, d’une image. La grande force, puisqu’une image est plus directe, plus rapide, plus efficace qu’un long texte – les géographes le savent bien, pour qui rien ne remplacera jamais une carte, un croquis, un schéma. Le grand risque, puisque l’image se pose comme une réalité, alors qu’elle n’est jamais qu’une construction, qu’elle soit photographie de presse, fresque médiévale, peinture rupestre[21]. L’image peut donc être trompeuse : elle peut jouer comme un argument d’autorité, provoquer un effet de réel tel qu’il empêcherait la discussion. Il faut donc souligner ce que ces images ont d’artificiel : un nuage de mots dépend des mots retenus, traduits, fusionnés ; une courbe obtenue sur Ngram Viewer n’interroge pas l’ensemble de la littérature mondiale, mais seulement les ouvrages numérisés par Google ; une carte ne reflète que les informations que son auteur a voulu y figurer. Autrement dit, ces images ne pourront ni ne devront jamais être présentées telles quelles : pour être utilisables, elles nécessitent une analyse poussée, non seulement pour expliciter les critères retenus dans leur fabrication, mais surtout pour analyser les résultats obtenus.
C’est là, en effet, le dernier point commun de ces trois techniques. Si elles permettent de présenter différemment des informations, et offrent ainsi de nombreuses possibilités, notamment sur le plan pédagogique, elles contribuent surtout à produire de nouveaux objets, qui peuvent à leur tour être commentés et analysés. Ces techniques doivent donc être mobilisées au cours de la recherche en elle-même et pas seulement lors de la phase de rédaction : elles permettent en effet de voir différemment certains aspects. En changeant de mode de représentation – on passe d’un texte à un nuage de mots, d’un ensemble de livres à une courbe, d’informations éparpillées à une carte – on peut redécouvrir des objets qui, à force d’être côtoyés, sont trop connus. Bref, ces techniques mettent en œuvre des processus de défamiliarisation, au sens de Carlo Ginzburg[22] : elles rendent autre, elles mettent à distance. On en arrive ainsi à une formulation paradoxale : ces images, élaborées à l’origine pour mieux présenter des sources, des données historiographiques ou des cartes, servent au final à les mettre à distance, permettant ainsi de mieux les observer.
[1] En particulier Catherine Kikuchi, Annabelle Marin, Marine Crouzet.
[2] Voir Marie Bouhaïk-Gironès, « L’Historien face à la littérature : à qui appartiennent les sources littéraires médiévales ? », dans Être historien du Moyen Âge au XXIe siècle. Actes des congrès de la Société des historiens médiévistes de l’enseignement supérieur public, 38e congrès, Paris, Publications de la Sorbonne, 2007, p. 151-161.
[3] https://en.wikipedia.org/wiki/Tag_cloud.
[4] Edition utilisée : Guibert de Nogent, Dei Gesta per Francos, éd. R.B.C. Huygens, Turnhout, Brepols, 1996.
[5] Édition utilisée : Guillaume de Tyr, Historia rerum in partibus transmarinis gestarum, dans Recueil des Historiens des Croisades, Historiens Occidentaux, tome I, Paris, Imprimerie Nationale, 1894, p. 3-1155.
[6] Édition et traduction utilisée : Usâma ibn Munqidh, Des enseignements de la vie. Souvenirs d’un gentilhomme syrien du temps des Croisades, trad. fr. André Miquel, Paris, Imprimerie Nationale, 1983.
[7] Pierre Bayard, Le Plagiat par anticipation, Paris, Éditions de Minuit ; Pierre Bayard, Demain est écrit, Paris, Éditions de Minuit, 2005.
[8] Jean Flori, Chroniqueurs et propagandistes. Introduction critique aux sources de la première croisade, Genève, Droz, 2010.
[9] Voir les outils proposés par le site Weblettres : http://www.weblettres.net/sommaire.php?entree=20&rubrique=75&sousrub=251.
[10] Voir Claire Lemercier et Claire Zalc, Méthodes quantitatives pour l’historien, Paris, La Découverte, 2007.
[11] Voir https://books.google.com/ngrams/info.
[12] Voir le résumé de Christian Lauranson-Rosaz, « La Mutation féodale: une question controversée », dans Przemyslaw Urbanczyk (dir.), Europe around the year 1000, Varsovie, Institue of Archaeology and Ethnology, Polish Academy of Sciences, 2001, p. 11‑40.
[13] Florian Mazel, Féodalités 888-1180, Paris, Belin, 2010.
[14] Ce terme étant également un mot du vocabulaire courant, les résultats sont probablement un peu biaisés ici.
[15] Voir Alain Guerreau, Le Féodalisme. Un horizon théorique, Paris, Le Sycomore, 1980.
[16] Deux en particulier : après 1945, de plus en plus de livres sont publiés chaque année et donc la proportion de termes comme « Moyen Âge » ne peut que diminuer ; et, corrélativement, la proportion de livres numérisés avant 1945 est forcément plus grande, et donc la fréquence d’utilisation des termes est forcément, après 1945, sous-estimée.
[17] Voir Joseph Morsel, L’Histoire (du Moyen Âge) est un sport de combat… Réflexions sur les finalités de l’histoire du Moyen Age destinées à une société dans laquelle même les étudiants d’histoire s’interrogent, Paris, LAMOP, 2007 (texte disponible en ligne à cette adresse https://lamop.univ-paris1.fr/IMG/pdf/SportdecombatMac.pdf.)
[18] Un immense merci à Lilian Besson, mon frère, pour son aide inappréciable sur ce point.
[19] Patrick Boucheron (dir.), ouvrage coordonné par Julien Loiseau, Pierre Monnet et Yann Potin, Histoire du monde au XVe siècle, Paris, Fayard, 2009.
[20] Ivan Jablonka, L’Histoire est une littérature contemporaine. Manifeste pour les sciences sociales, Paris, Seuil, 2014 : « non seulement oser des expériences nouvelles, mais projeter sur mille supports les outils d’intelligibilité que nos devanciers ont forgé […] À cet égard, Internet est notre plus fidèle allié […] Il nous revient de créer de nouveaux objets intellectuels pour répondre à la crise qui frappe l’université, ainsi que l’édition en sciences humaines. À nous d’attirer les étudiants, les lecteurs, de nouveaux publics. À nous de réinventer notre métier ».
[21] Voir, dans l’ordre, l’analyse de la célèbre photo “La jeune fille à la fleur” de Marc Riboud (1967) proposée par Régis Dubois sur le site Le sens des images (http://lesensdesimages.com/2012/06/05/analyse-dun-photographie-la-fille-a-la-fleur-de-marc-riboud-1967/) ; Patrick Boucheron, Conjurer la peur. Sienne, 1338 : essai sur la force politique des images, Paris, Seuil, 2013 ; François-Xavier Fauvelle-Aymar, Vols de vache à Christol Cave. Histoire critique d’une image rupestre d’Afrique du Sud, Paris, Publications de la Sorbonne, 2014.
[22] Carlo Ginzburg, À distance. Neuf essais sur le point de vue en histoire, Paris, Gallimard, 2001.